es作为一个分布式的存储和检索系统,每个文档根据 _id 字段做路由分发被转发到对应的shard上。
搜索执行阶段过程分俩个部分,我们称之为 Query Then Fetch
query-查询阶段
当一个search请求发出的时候,这个query会被广播到索引里面的每一个shard(主shard或副本shard),每个shard会在本地执行查询请求后会生成一个命中文档的优先级队列。
这个队列是一个排序好的top N数据的列表,它的size等于from+size的和,也就是说如果你的from是10,size是10,那么这个队列的size就是20,所以这也是为什么深度分页不能用from+size这种方式,因为from越大,性能就越低。
es里面分布式search的查询流程如下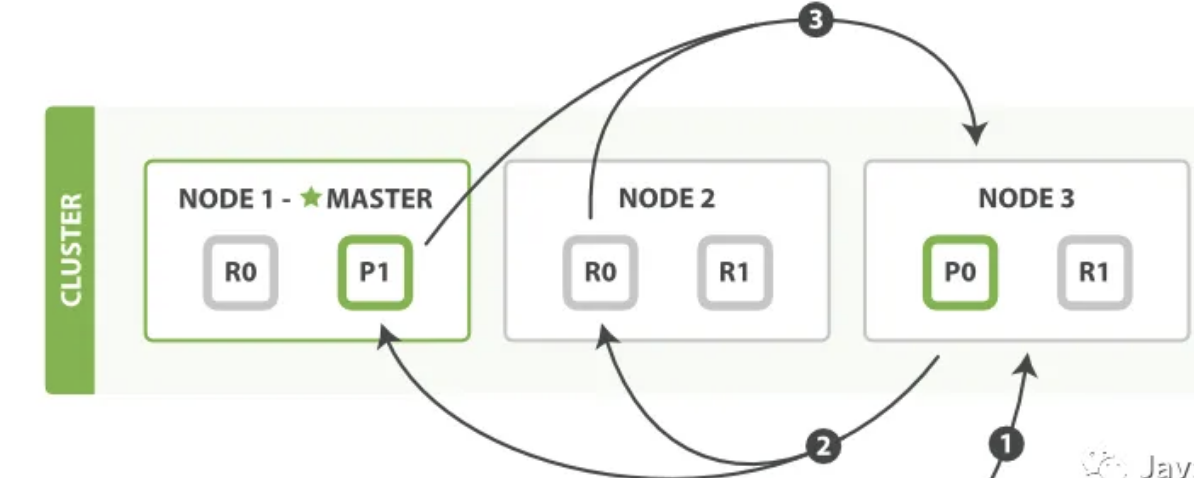
查询阶段包含以下三个步骤:
客户端发送一个 search 请求到 Node 3 , Node 3 会创建一个大小为 from + size 的空优先队列。
Node 3 将查询请求转发到索引的每个主分片或副本分片中。每个分片在本地执行查询并添加结果到大小为 from + size 的本地有序优先队列中。
每个分片返回各自优先队列中所有文档的 ID 和排序值给协调节点,也就是 Node 3 ,它合并这些值到自己的优先队列中来产生一个全局排序后的结果列表
fetch - 读取阶段
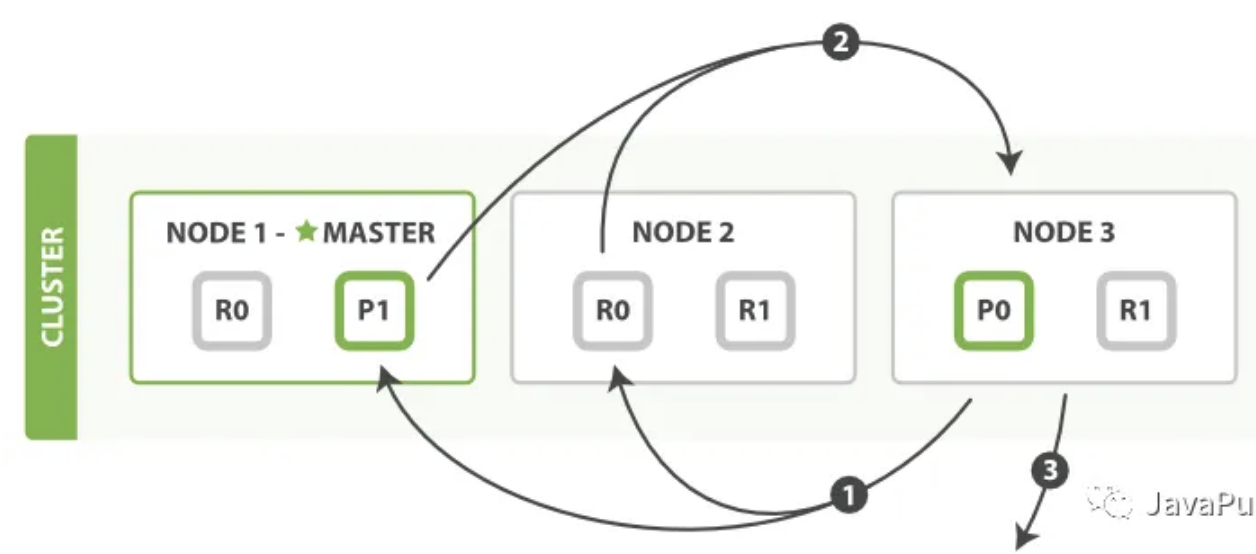
分布式阶段由以下步骤构成:
- 协调节点辨别出哪些文档需要被取回并向相关的分片提交多个 GET 请求。
- 每个分片加载并 丰富 文档,如果有需要的话,接着返回文档给协调节点。
- 一旦所有的文档都被取回了,协调节点返回结果给客户端。
协调节点首先决定哪些文档 确实 需要被取回。例如,如果我们的查询指定了 { “from”: 90, “size”: 10 } ,最初的90个结果会被丢弃,只有从第91个开始的10个结果需要被取回。这些文档可能来自和最初搜索请求有关的一个、多个甚至全部分片。
协调节点给持有相关文档的每个分片创建一个 multi-get request ,并发送请求给同样处理查询阶段的分片副本。
分片加载文档体– _source 字段—如果有需要,用元数据和 search snippet highlighting 丰富结果文档。一旦协调节点接收到所有的结果文档,它就组装这些结果为单个响应返回给客户端